MapReduce in Hadoop

Although MapReduce is not much used in solving Big Data problems nowadays because of its poor performance compared to spark. But it's still a very good approach to understanding how distributed computing works in Big Data.
What is Hadoop MapReduce?
Hadoop MapReduce is a framework used for writing applications to process large datasets in a distributed manner. As its name suggests it uses the Map-Reduce paradigm internally.
The Map Reduce paradigm is having 2 phases
1. Map Phase (local processing)
The map phase works on the principle of data locality, meaning the code written by the developer goes to data nodes and not vice versa. In Hadoop, the mappers (map programs running on multiple data nodes) accept input and output as key-value pairs only
2. Reduce Phase (combined aggregation)
All the output generated in map phases is combined in reduce phase to give a collective final result. In Hadoop, the reducer(reduce program running on a single data node) also accepts input and output as key-value pairs only.
Example
Consider a word count problem where the input is simple text containing many words and the output needs to be key-value pairs having the keys as words and the values as their count.
Solution
consider that input data is already present in HDFS data nodes and mappers are running on the data nodes where the blocks of these data are present. The number of mappers is the same as the number of blocks so we have 1 mapper running per block.
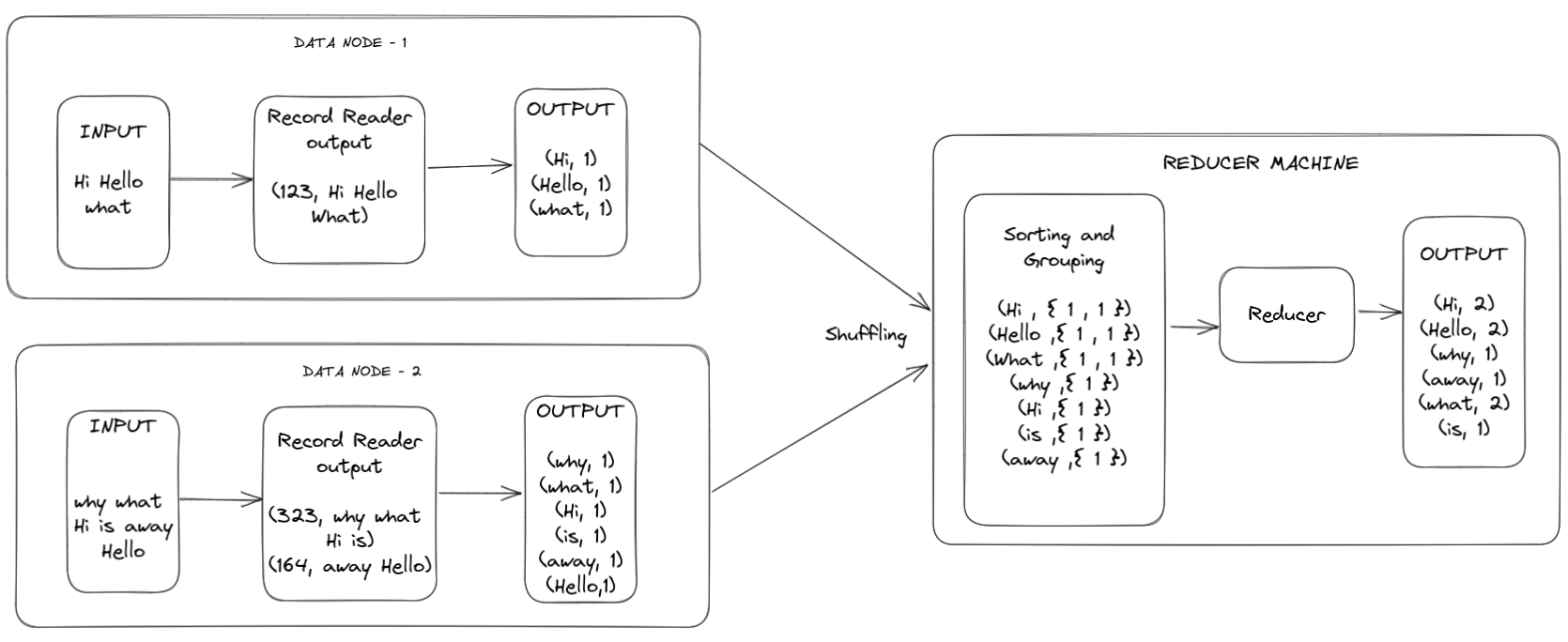
Steps
1. Record reader will read the data from the block and convert each record into a key-value pair by attaching a random address as the key.
2. Output of the first step is provided to the mapper (this mapper code is written by the developer) where the key is ignored and words are split into an array. Then an integer value '1' is attached as a value for each word giving a key-value output having the key as the word and value as 1 for all words.
3. Mapper output is transferred to the reducer machine (1 of the data nodes) and sorting and grouping happen in the reducer machine giving output as key-value pair having key as word and value as all the values with the same key aggregated into a list.
4. Steps from 1 to 3 run in parallel for all those mappers that are running on different data nodes.
5. Output from step 3 is provided to the reducer program (written by the developer) where all the values are summed up resulting in key-value pairs having the key as a word and the value as its total count.
Optimizations in Hadoop MapReduce
there are mainly two basic types of optimizations
1. Combiner (local aggregation)
the basic idea behind the combiner is local aggregation. Instead of passing all the values as it is to the reducer for aggregation we first do most of the possible aggregation locally first on the mapper machine itself.
This increases the performance many times as the data transferred while shuffling is less comparatively and we get fastness from parallelism also as mappers on different data nodes run in parallel.
NOTE: we need to be very careful while using the combiner and use it only for problems that can be divided into subproblems of the same type with a small dataset.
2. Adding more reducer
We can add more reducers for a MapReduce job if the reducer is burdened and runs very slowly. when more than 1 reducer is used the output data from each mapper is partitioned and the number of partitions is equal to the number of reducers all the data of 1 partition goes to only 1 reducer.
Hadoop uses an internal consistent hash function to make sure the same keys go to the same partition and further to the same reducer to maintain the sanity of the final result. we can also use our custom hash function for this, but we need to be sure the hash function is always consistent meaning it gives the same result for the same key always.



