Spark Stages, Tasks, and Jobs

There are mainly 3 components in spark UI
Jobs
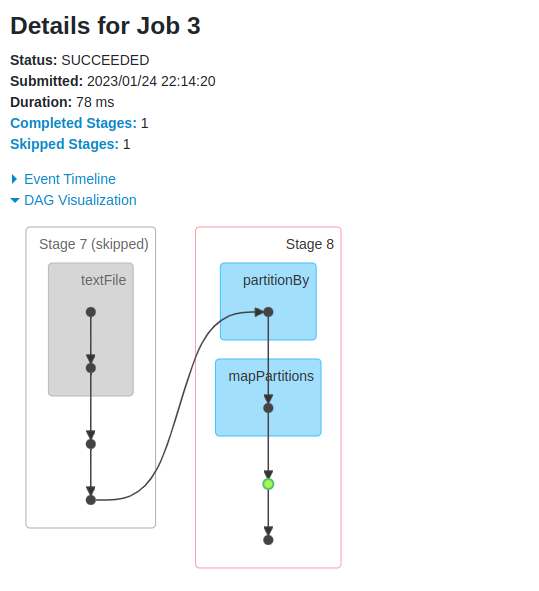
A spark application can have multiple jobs based on the number of actions (#jobs =#actions) in the application. These jobs can have a common rdd somewhere in the execution map or they can be separate also starting from the base rdd. All the transformations are calculated from starting in a job however spark provides some optimizations and in case there are common stages than the output of the last common stages which was calculated by the other job is taken as it is and further transformations are done on top of that.Stages
The boundary of a stage is defined by wide transformations. whenever there is a wide transformation a new stage is created in the spark.
What are wide & narrow transformations?
All the transformations that have involves data shuffling ( data transfer from 1 machine to different machines) are called wide transformations like reduceByKey, GroupByKey, etc. And other transformations that do not include the shuffling of data are called narrow transformations like filter, map, etc.
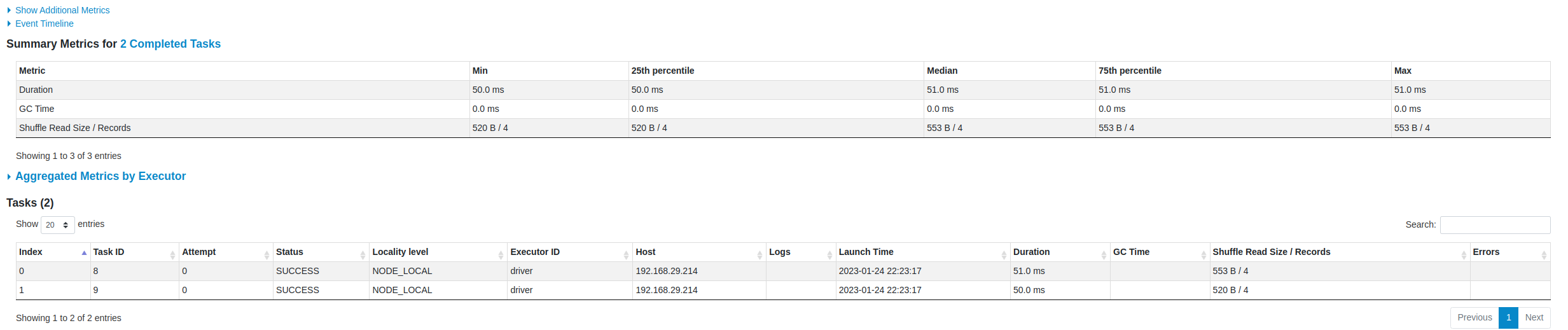
Tasks
Each stage can have multiple tasks and each task represents an executor task code running on 1 partition so the total number of partitions is equal to the total number of partitions in an RDD.
Cache and Persist
when we are having many multiple actions in a spark application and a lot of common transformations are being done we can Cache or Persist the resultant RDDs into memory or/and disk for quicker job completion.
Cache stores the result in memory if sufficient memory is available it will store it else will continue without caching and will not give any error.
Persist is the same as a cache but it comes with different caching levels like -
DISK_ONLY - store the data on the disk only in serialized format
MEMORY_ONLY - it is the same as cache (storing data in non-serialized format)
MEMORY_AND_DISK - if enough memory is available store it in memory in non-serialized format else store it in memory by removing some blocks plus store evicted blocks in the disk in serialized format.
OFF_HEAP - stores the data in raw memory outside JVM. (it is unsafe as garbage collection needs to be taken care of externally from JVM but it is more performant and fast)
Usage -
some_count = cols_one.reduceByKey(lambda x,y: x+y).cache()
scount = cols_one.reduceByKey(lambda x,y: x+y).persist(StorageLevel.MEMORY_AND_DISK)


