Spark on YARN architecture

When we talk about spark on top of Hadoop its generally Hadoop core with Spark compute engine instead of MapReduce, i.e (HDFS, Spark, YARN)
Spark follows a master-slave architecture where the master is called a Driver in spark and is responsible for analyzing the requirement, dividing the work among multiple executors, requesting resources from the resource manager, monitoring the executing tasks, rerunning the tasks if it fails, etc.
And slaves are called executors in spark and their responsibility is to execute their individual tasks and report the computing status to the driver.
We can run a spark application in two ways
Client mode
In client mode, we can run spark commands using the spark-shell utility or pyspark utility. in which a Driver is created locally.
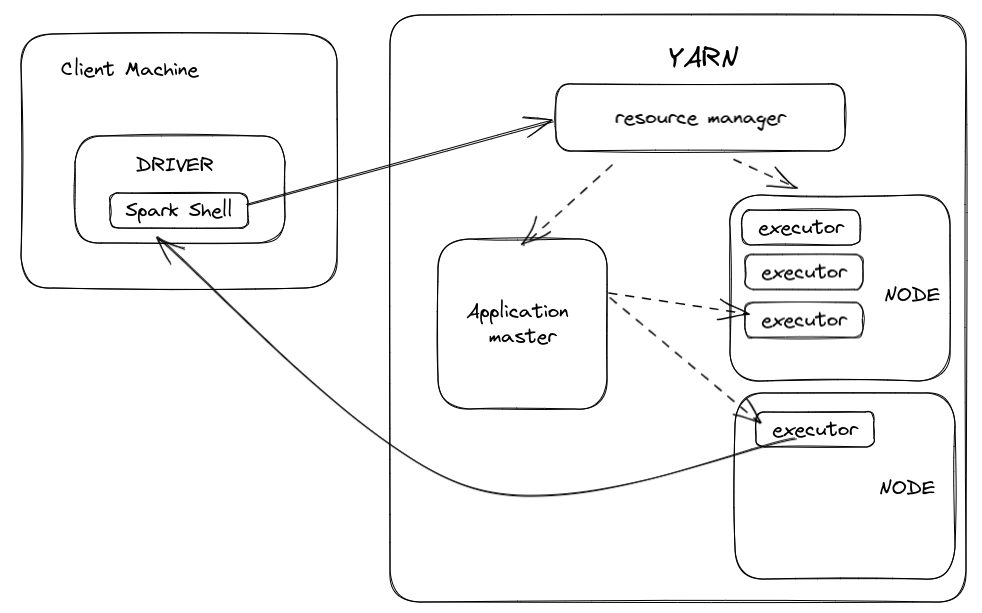
Steps -
A driver is created in the Client machine which creates a spark session ( storage where all the state variables and status of current events are stored) is created.
Spark Session sends a request to the YARN resource manager.
YARN resource manager creates an application master on 1 of the node in hadoop cluster
The application master requests resources from YARN resource manager for launching executors on them.
YARN resource manager allocates resources in terms of containers to the Application master
Application master launches executors on the allotted containers
Executors directly communicate with the driver present on the client machine.
Cluster mode
In this mode, we bundle the application and send the request using spark-submit. Here everything remains the same but the driver runs on the application master instead of the client machine.


