HDFS Recovery mechanisms

Data nodes in HDFS are generally of commodity hardware which is low-priced but goes down very frequently.
What happens to the data when a Data Node goes down?
whenever a block is entered in HDFS, it is always replicated to multiple nodes. the number of replicas is based on the replication factor (by default 3) property of HDFS set by the Hadoop admin while configuring the Hadoop cluster.
So, whenever a data node goes down its heartbeat signal is not reached the name node and after 10 consecutive heartbeat signal failures, the data node is considered dead/slow and not fit to serve the data. after this, the other data nodes where replicas are present start serving the requests for lost blocks.
Meanwhile, the Name node creates 1 more replica for lost blocks to maintain the replication factor and updates the metadata table (block mapping with data nodes).
What happens when the name node goes down?
The name node is generally of high-quality hardware but it can also go down sometime. In Hadoop 1, Name node failure was a single point of failure which caused complete downtime.
From Hadoop 2 onwards many name node recovery mechanisms were introduced and one of the basic recovery mechanisms is check-pointing.
Checkpointing Process
In this recovery mechanism, there are two name nodes first is the primary name node (actively serving the traffic) and the second is the secondary name node which does the checkpointing.
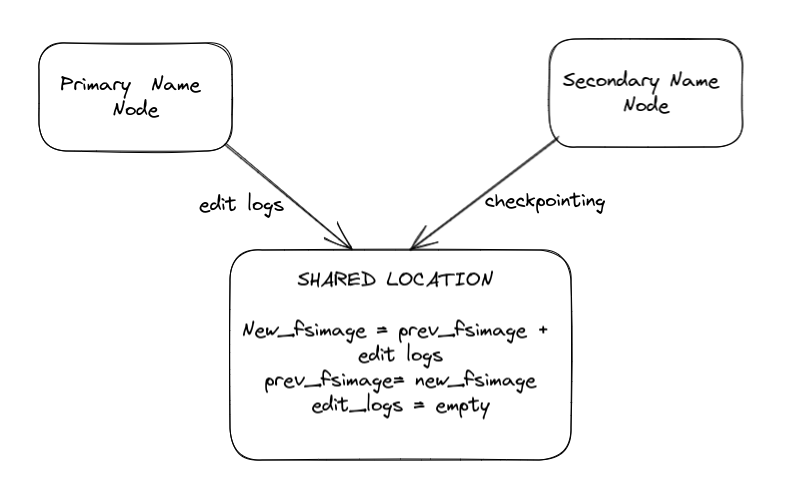
The primary name node saves the edit logs(new entries/deletions in HDFS) to a shared location.
The secondary name node takes these edit logs and merges them with the previous fsimage (file system image - a snapshot of the whole file system taken sometime before now) to get the new latest fsimage representing the current file system state.
Once edit logs are merged and this new fsimage is obtained, the secondary name node empties the edit logs for the next cycle.
This whole process of merging edit logs with the previous fsimage and generating a new fsimage is known as checkpointing. checkpointing is done by a secondary node as it is a very compute-heavy task and the primary node is already busy in serving the traffic.
So, When the primary name node goes down, the secondary name node becomes the primary node and starts serving the traffic. meanwhile, the Hadoop admin brings up a new secondary name node to continue the checkpointing process.



