Basic HDFS Architecture

What is HDFS?
HDFS (Hadoop Distributed File System) is 1 of the 3 Hadoop core components. As its name suggests it's a distributed storage file system where large files are divided into multiple blocks of size 128mb (64mb in Hadoop 1) and stored across multiple nodes (computer systems available over a network).
There are mainly two components in HDFS architecture
Data Node
Data nodes are those where actual data is stored and accessed by the clientName Node
Name Node is where the mapping of file blocks and data node location are kept as metadata.
Functions of Name Node
1. It keeps metadata of files in a table-like structure that defines the mapping of files and their blocks and on which data node that particular block is stored.
| file-name | block-name | data-node |
| file1 | b1 | Data_Node_3 |
| file1 | b2 | Data_Node_4 |
| file2 | b1 | Data_Node_2 |
| file2 | b3 | Data_Node_1 |
It makes sure that the number of replicas for a block is always maintained even when there is a data node failure. (creates new replicas and updates the mapping metadata)
Provides the location of data nodes where the requested file is kept.
Monitors data node's health checks.
Functions of Data Node
1. Stores the actual data in the form of blocks
2. Sends block report (status of corrupted blocks ) to name node
3. Sends heartbeat signal every 3 seconds (by default) to name node
4. Sends the requested data blocks to the client whenever requested
Steps for accessing data in HDFS
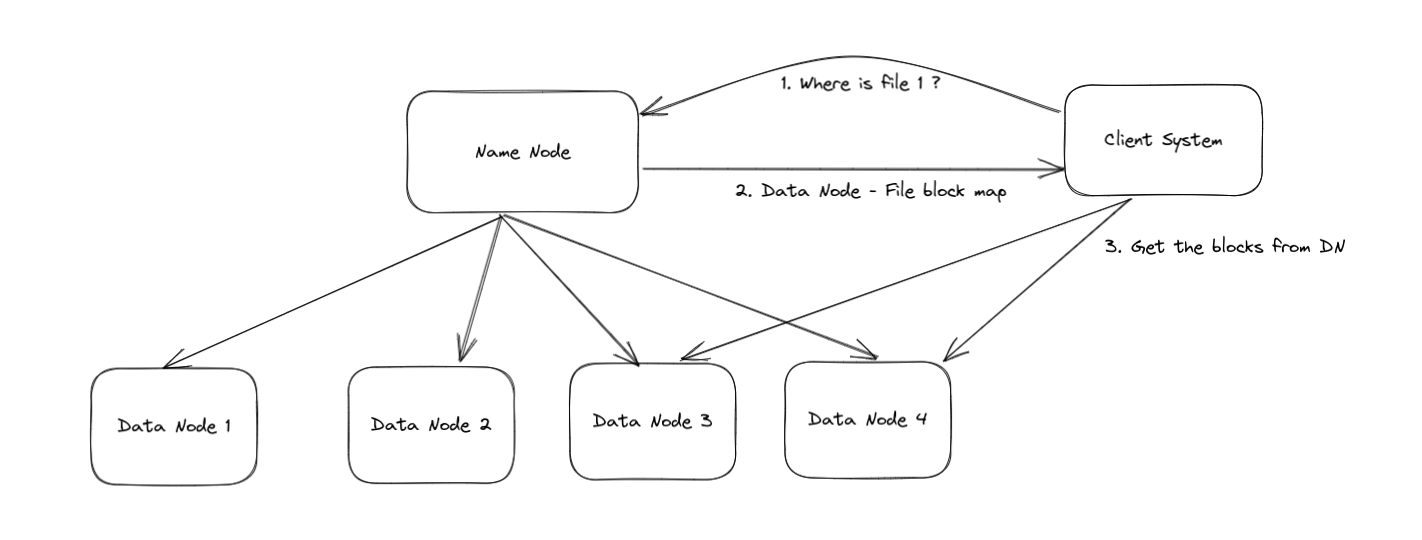
Client requests to access a file are sent to the name node
The name node checks in the metadata if the file is present it sends the locations of blocks and data node where these blocks of requested files are kept.
The client Requests the data nodes to get the blocks of the requested file.
The requested data is merged on the client machine and the file is received.



